Research/Blog
End-to-End Object Detection with Transformers
Recently, I presented a session on End-to-End Object Detection with Transformers at CellStrat AI Lab.
Introduction
The goal of object detection in computer vision is to identify and locate objects in an image or video. The object detection methods can be divided into two categories as Two stage detectors and Single stage detectors. In two stage detectors such as RCNN, Faster RCNN etc. first a large number of coarse regions of interests (ROI) are proposed and in second stage the proposed regions are processed further for object classification and bounding box regression. Two stage detectors have high object detection and localization accuracy but generally slow. In singe stage detectors such as YOLO, SSD etc. the bounding boxes are predicted directly without the need of region proposals. Single stage detectors are fast but relatively less accurate. Read this blog for an overview of object detection.
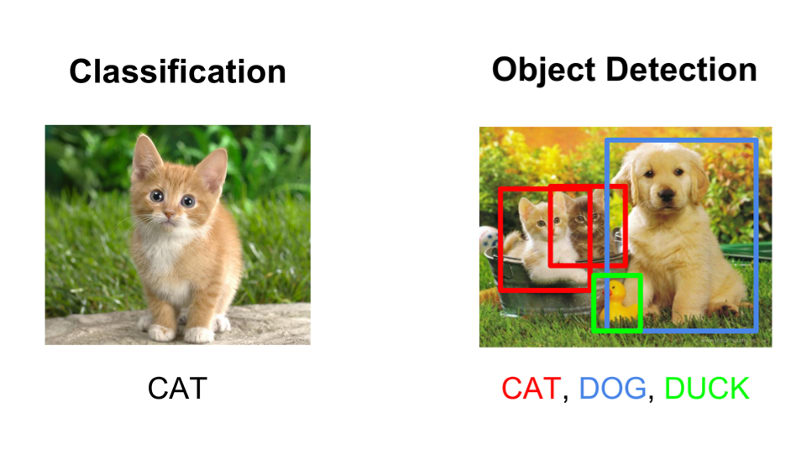
Recently, Facebook AI (FAIR) launched a new object detection method Detection Transformers (DETR) with an interesting approach of using Transformers for object detection. Till now, Transformers have been widely known to be used mainly for NLP tasks. Transformers are deep learning architecture that uses a powerful mechanism called self-attention that focuses on certain part of the sequences. DETR has completely changed the approach of object detection from previous works and successfully integrated Transformers in object detection pipeline.
DETR Framework
DETR considers the object detection as a direct set prediction problem and eliminates the need of hand designed components such as Non-maximum suppression, Anchor boxes which were used in Faster RCNN. DETR predicts an unordered set of all objects present in an image. A set is represented by the class of the object and the bounding box co-ordinates tightly surrounding the object.
The three main ingredients of this new framework are:
- Detection Transformer
- A set-based global loss that forces unique predictions via bipartite matching
- Encoder-Decoder architecture

Bipartite matching loss
DETR frameworks uses a set based global loss that enforces unique prediction through bipartite matching. DETR always infers a fixed set of ‘N’ predictions where ‘N’ is significantly larger than the number of classes. Let y denote the ground truth set of objects and y-hat the set of N predictions. The bipartite matching between the ground truth and predicted is achieved by Hungarian algorithm which determines the optimal assignment between ground truth and prediction and explained in next section. The bipartite matching is denoted as the sum of matching loss Lmatch with optimal assignment denoted by

Lmatch the matching loss is the sum of class prediction loss and bounding box difference loss.

Hungarian algorithm
Hungarian method is a combinatorial optimization algorithm that solves the assignment problem in polynomial time O(n^3). The steps of Hungarian method are as follows and illustrated using an example in the figure.
- Step 1 – Row reduction : Subtract the smallest entry in each row from all the other entries in the row. This will make the smallest entry in the row now equal to 0.
- Step 2 – Column reduction : Subtract the smallest entry in each column from all the other entries in the column. This will make the smallest entry in the column now equal to 0.
- Step 3 – Test for an optimal assignment : Draw lines through the row and columns that have the 0 entries such that the fewest lines possible are drawn.
- Step 4 – Shift zeros : If there are ‘n’ lines drawn, an optimal assignment of zeros is possible and the algorithm is finished – Go to the Step 5. If the number of lines is less than ‘n’, then the optimal number of zeroes is not yet reached – do shifting : Find the smallest entry not covered by any line. Subtract this entry from each row that isn’t crossed out, and then add it to each column that is crossed out.
- Step 5 – Making the final assignment

Encoder-decoder architecture
DETR uses the standard transformer encoder-decoder architecture. Read this blog for details understanding of transformer architecture. Given an input image, the image is first passed through a conventional CNN backbone to extract feature maps. The feature maps are then supplemented with positional encoding before it is passed through the encoders. Each encoder has the standard architecture with multi-head self attention units and FFN. The decoder also follows the standard architecture which takes as inputs a fixed number of learned positional embedding called as object queries and encoder embedding to provide the output embedding. The output embedding is then passed through FFN that predicts the class and bounding box co-ordinates.

DETR model uses the encoder-decoder architecture to globally reason about the different objects present in the image and also the relation between each pair of objects taking into account the whole image context.
The decoder typically attends to the object extremities such as legs and heads as shown in the image below.

Panoptic segmentation
Panoptic segmentation is the combination of semantic segmentation and instance segmentation so that all the image pixels are assigned a class and each object instance has a unique segmentation mask. Similar to how Faster R-CNN was extended Mask R-CNN DETR can be extended by adding a mask head on the decoder outputs. Figure below illustrate how panoptic segmentation can be achieved by adding a FPN style architecture to the decoder outputs.

Results
DETR framework was trained on COCO 2017 dataset with 118k training images and 5k validation images. DETR was trained using two backbones ResNet50 and ResNet101. DETR was able to achieve significantly better Average Precision on the 5K COCO validation set as compared to Faster RCNN. However, the downside of the DETR is that it has not so good performance for smaller objects which is expected to be solved in the future versions of DETR.

We tested the DETR on two test images using pre-trained ResNet101 DETR model. The model performed really well in both test images. In test image 1 object class of COCO dataset such as person, couch, laptop potted plant and vase with multiple instances were identified correctly and accurately. In test image 2, objects such as elephants, giraffe, zebra and bird were identified correctly and accurately.


Conclusion
A new paradigm of object detection method is introduced through DETR and it is the first object detection framework that successfully integrated Transformers in object detection pipeline. DETR will help to bridge the gap between NLP and computer vision in future research and innovation. DETR is simple to implement and does not require special libraries. The inference code can be implemented in 50 lines of code. DETR can also be used in model interpretation by attention mechanism visualization which highlights the parts of the image that caused the prediction.
References
- 1.https://arxiv.org/pdf/2005.12872.pdf
- https://ai.facebook.com/blog/end-to-end-object-detection-with-transformers/
- https://github.com/facebookresearch/detr
- https://analyticsindiamag.com/object-detection-with-transformers/
- https://arxiv.org/pdf/1506.01497.pdf
- https://arxiv.org/pdf/1907.09408.pdf
- https://www.michaelphi.com/illustrated-guide-to-transformers/
- https://giou.stanford.edu/
- https://brilliant.org/wiki/hungarian-matching/
- https://www.youtube.com/watch?v=cQ5MsiGaDY8/
- Introduction to object detection